구름톤 딥다이브 백엔드 과정 1차 프로젝트
잇츠잇츠
구름톤 딥다이브 백엔드 과정 쿠팡이츠 클론 코딩 프로젝트
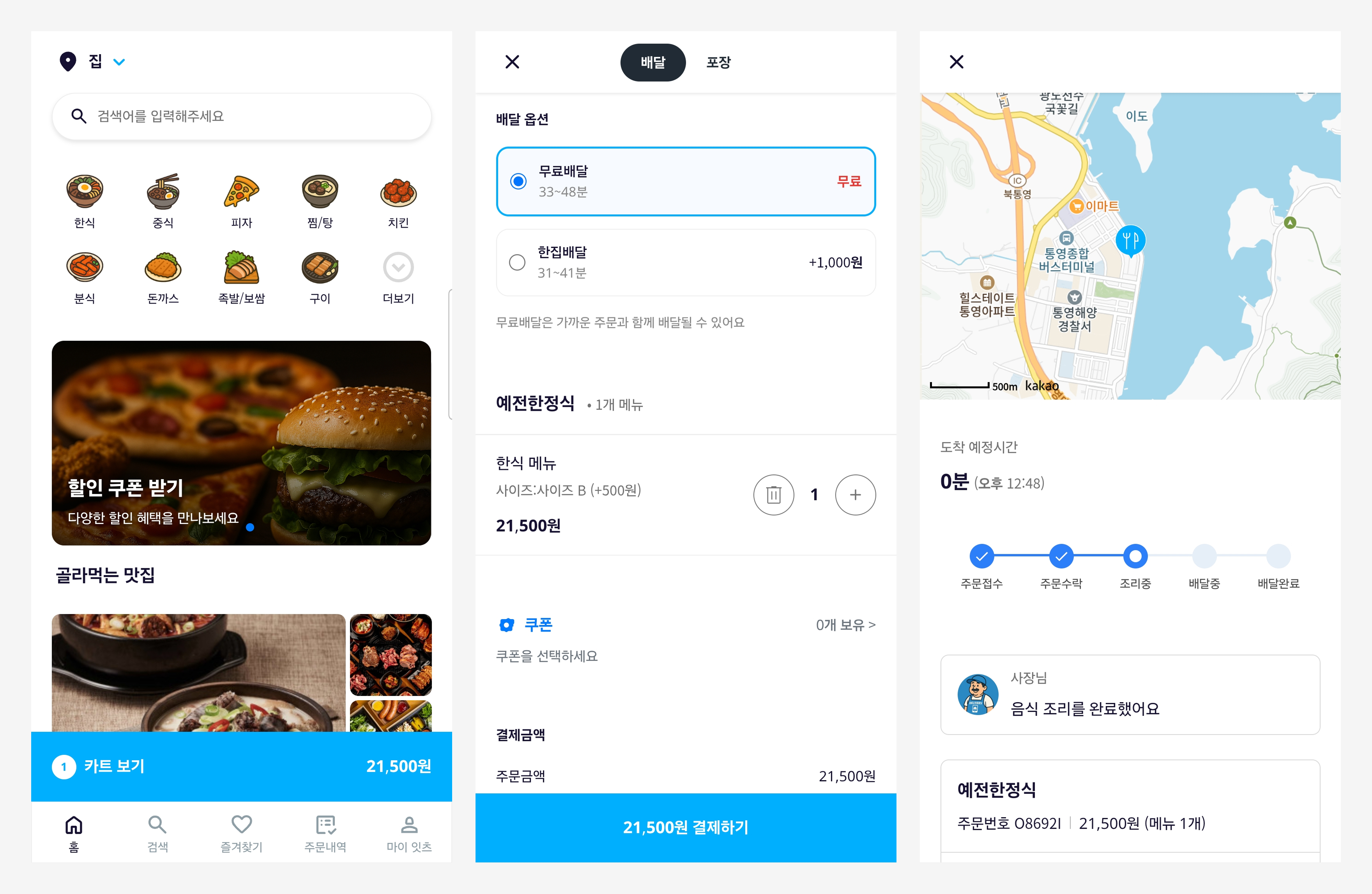
구름톤 딥다이브 백엔드 과정의 1차 프로젝트로, 쿠팡이츠 서비스에 대한 클론코딩 프로젝트를 진행하였습니다.
웹 기술을 이용하여 고객, 가맹점, 라이더 세 가지 역할의 사용자에 대한 주문/배달 프로세스를 개발하였습니다.
기간 및 참여 인원
- 기간: 2025-05-28 ~ 2025-07-15
- 인원: 6명
역할
⚙️ Backend 개발 (기여도 25%)
- 가게 조회 및 검색 기능 개발
- 가까운 순 조회 관련 부하 테스트 및 성능 개선
- 메뉴 관리 기능 개발
- 전국일반음식점표준데이터 이용, 형식 변환 및 더미데이터 생성
☁️ 인프라 (기여도 100%)
- AWS 서비스 관리 및 배포
- Github Actions 이용 Docker, React 빌드 및 배포 구성
🌐 Frontend 개발 (기여도 30%)
- 공용 컴포넌트 작성
- 백엔드 ↔ 프론트엔드 연동
문제 해결 및 성능 개선
가까운 순 조회시 인덱스 사용 성능 개선
문제 배경
가게 목록 조회시 나와 가까운 순으로 정렬하는 기능을 제공함. 이때 거리는 요청하는 회원에 따라 달라지기에 캐싱에 어려움이 있음. 따라서 부하테스트의 대상으로 결정함.
부하테스트를 위해 등록된 가게의 수를 66만 개로 늘려 테스트를 진행함.
기존 가까운 순 조회시 쿼리에서 ST_Distance_Sphere 함수를 사용하여 두 좌표(경도, 위도) 사이 거리를 계산함. 그러나 일부 칼럼에 대한 인덱스만 사용되어 66만개 행 중 16만 3천개의 행에 대해 거리가 계산됨.
K6 이용 300개의 virtual user로 60초간 부하테스트 결과 581개 요청 중 120개로 20.65%의 요청만 성공하고 80%는 실패함.
(원인은 DB 커넥션 풀 소진으로 인한 타임아웃)
개선 방법
MySQL은 좌표 같은 공간 검색을 위해 SPATIAL INDEX를 제공함. 공간 인덱스를 추가하였으나 ST_Distance_Sphere 함수는 인덱스를 활용할 수 없었음.
따라서 기존 쿼리의 WHERE 조건절에 한쪽 변이 약 5km인 정사각형을 만들어 필터링한 후 남은 좌표에 대해 거리를 계산 및 정렬하도록 변경함. 쿼리 실행 계획에 따르면 66만개 행 중 376개 행에 대해 거리가 계산됨.
결과
이전과 동일한 조건으로 부하테스트 결과 3401개 요청에 대해 100% 성공함.
사용 기술
- Backend:
JavaSpring bootJPASpring Security - Frontend:
ReactRedux - DB:
MySQLRedis - CI/CD :
Github Actions - 인프라 :
AWS FargateAWS S3Docker - 테스트:
JUnit 5 - 모니터링 및 성능테스트:
PrometheusGrafanaK6 - 문서화 :
Swagger
구조
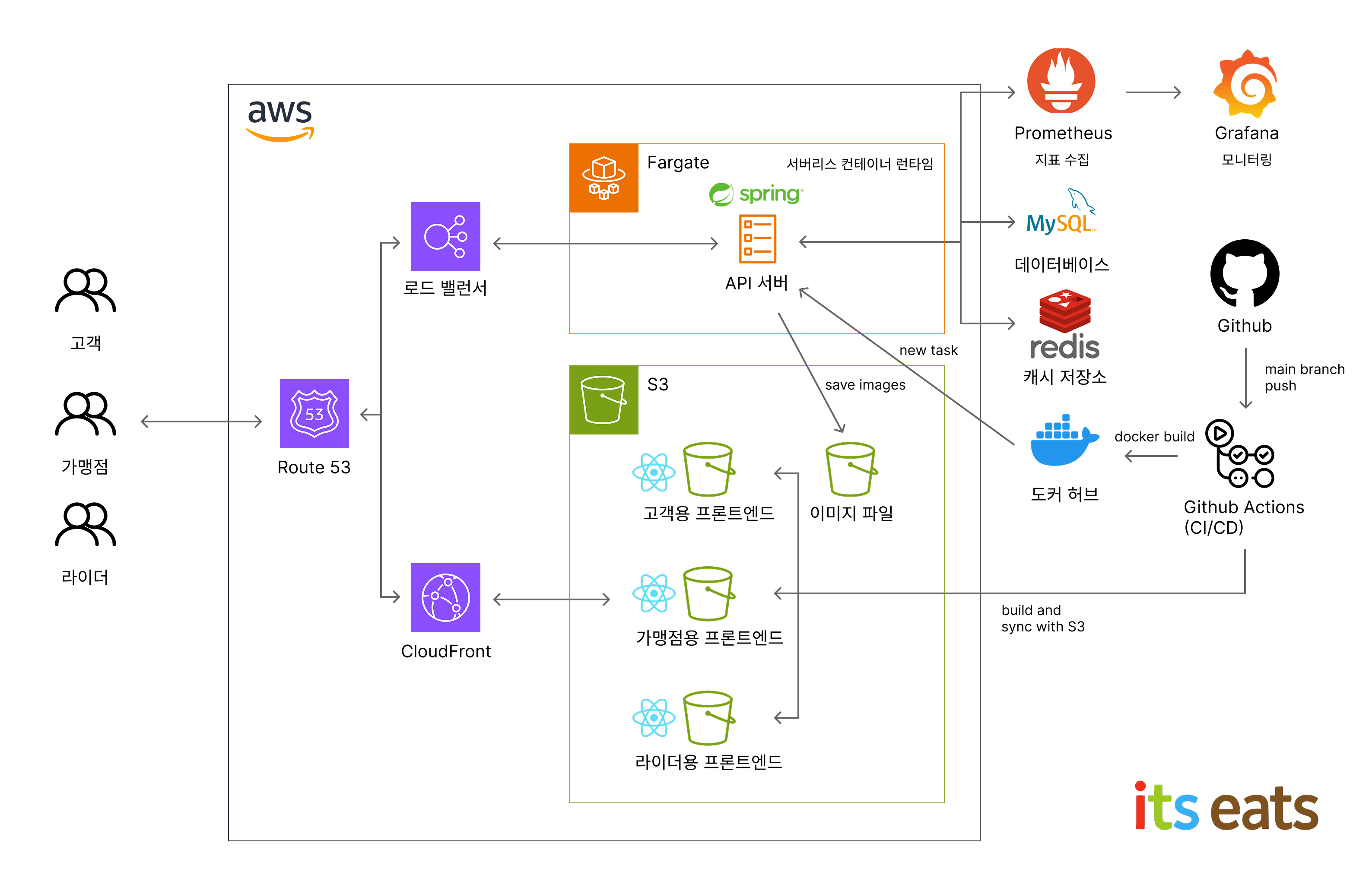
결과물